Day 1: Predict House Prices Using a Feedforward Neural Network (NN)
For this project, we’ll use a Feedforward Neural Network (NN) to predict the prices of houses based on various features such as number of rooms, area, location, etc. We’ll use Keras, a high-level API of TensorFlow, which makes building and training neural networks relatively easy.
Outline of the Solution:
- Dataset: We’ll use a sample dataset called California Housing Prices from the
scikit-learnlibrary to make things simple. This dataset has useful features for learning purposes. - Steps:
- Load the dataset
- Preprocess the data
- Split into training and testing datasets
- Build a neural network model
- Train the model
- Evaluate the model
Implementation
import pandas as pd
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import matplotlib.pyplot as plt
# Step 1: Load the data
data = fetch_california_housing(as_frame=True)
data_df = data.frame
# Step 2: Build the feature and target datasets.
X = data_df.drop('MedHouseVal', axis=1) # Feature Dataset
y = data_df['MedHouseVal'] # Target Dataset
# Step 3: Split the dataset into training and validation datasets.
# We will go with 80-20 ratio, training (80%) and validation (20%)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# Step 4: Scale the data
scaler = StandardScaler()
scaler.fit_transform(X_train)
scaler.transform(X_val)
# Step 5: Build the Neural Network Model
model = Sequential()
model.add( Dense(64, activation='relu', input_shape=(X.shape[1],)) )
model.add(Dense(32, activation='relu'))
model.add(Dense(1))
# Step 6: Compile the model
model.compile(optimizer='adam', loss='mse', metrics=['mae'])
# Step 7: Train the model
history = model.fit(X_train, y_train, validation_split=0.2, epochs=50, batch_size=32, verbose=1)
# Show the learning curve
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot()
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training and Validation loss across epochs')
plt.show()
# Step 8: Evaluate the model
test_loss = test_mae = model.evaluate(X_val, y_val)
print(f"Validation Mean Absolute Error: {test_mae}")
# Output:
# For Epochs - 50:
# Validation Mean Absolute Error: [0.6920378804206848, 0.6737860441207886]
# For Epochs- 10
# Validation Mean Absolute Error: [0.8164848685264587, 0.745993971824646]
# For Epochs - 6
# Validation Mean Absolute Error: [94.31477355957031, 7.9173150062561035]
# So 50 was a good number.
Here’s the step-by-step explanation of each part of the code:
Step 0: Importing Libraries
pandas as pd: Pandas is used to handle data in a structured format (DataFrames) which makes it easy to manipulate, explore, and clean data.fetch_california_housing: This function from sklearn allows us to load the California Housing dataset.train_test_split: This helps split the dataset into training and validation sets.StandardScaler: This is used to normalize the features to have zero mean and unit variance, which improves neural network performance.Sequential and Dense: These come from Keras (part of TensorFlow) and are used to define the structure of our neural network.matplotlib.pyplot as plt: This library is used to visualize the training history, such as the loss over epochs.
Step 1: Load the Data
fetch_california_housing(as_frame=True): Loads the dataset into a Pandas DataFrame for better readability and data manipulation.data.frame: The dataset is stored as a DataFrame called data_df, allowing us to easily view and work with the features and target values.
Step 2: Build the Feature and Target Datasets
X (Feature Dataset): Contains all the features that will be used to make predictions. We drop ‘MedHouseVal’ as it’s the target variable (i.e., what we want to predict).y (Target Dataset): Contains the target variable, which is the Median House Value (MedHouseVal). This is what the model will try to predict.
Step 3: Split the Dataset into Training and Validation Datasets
- We split the data into training (80%) and validation (20%) sets.
Training Data (X_train, y_train): Used to train the model.Validation Data (X_val, y_val): Used to evaluate the model’s performance on unseen data.- random_state=42 ensures the split is reproducible.
Step 4: Scale the Data
StandardScaler(): Initializes the scaler, which standardizes features by removing the mean and scaling to unit variance.scaler.fit_transform(X_train): Fits the scaler toX_trainand transforms it. This step calculates the mean and variance of the training set and then scales the data accordingly.scaler.transform(X_val): Scales the validation set using the same mean and variance calculated fromX_train. This ensures consistency between training and validation.
Step 5: Build the Neural Network Model
Sequential(): Initializes a simple linear stack of layers.model.add(Dense(64, activation='relu', input_shape=(X.shape[1],))):- Adds a Dense layer with 64 neurons and ReLU activation function.
input_shape=(X.shape[1],)defines the shape of the input, which matches the number of features.
model.add(Dense(32, activation='relu')): Adds another Dense layer with 32 neurons.model.add(Dense(1)): Adds the output layer with 1 neuron, which predicts the house price.
Step 6: Compile the Model
optimizer='adam': Adam is a popular optimizer that adjusts the learning rate to optimize training speed.loss='mse': Mean Squared Error is used as the loss function, as this is a regression problem (predicting a continuous value).metrics=['mae']: We use Mean Absolute Error (MAE) as an additional metric to evaluate the performance of the model.
Step 7: Train the Model
model.fit(): Trains the model using the training dataset.validation_split=0.2: During training, 20% of the training set will be used as validation data.epochs=50: The model will train for 50 complete passes through the entire training dataset.batch_size=32: The training dataset is divided into batches of 32 samples each, and the model will update its weights after each batch.verbose=1: Shows detailed logs during training.
Show the Learning Curve
history.history: Contains the training and validation loss values collected during training.pd.DataFrame(history.history): Converts the history object into a Pandas DataFrame for easy visualization..loc[:, ['loss', 'val_loss']].plot(): Plots the training loss and validation loss over the number of epochs.plt.xlabel('Epochs'), plt.ylabel('Loss'), plt.title(), plt.show(): Add labels, a title, and display the plot to visualize the model’s training and validation loss.
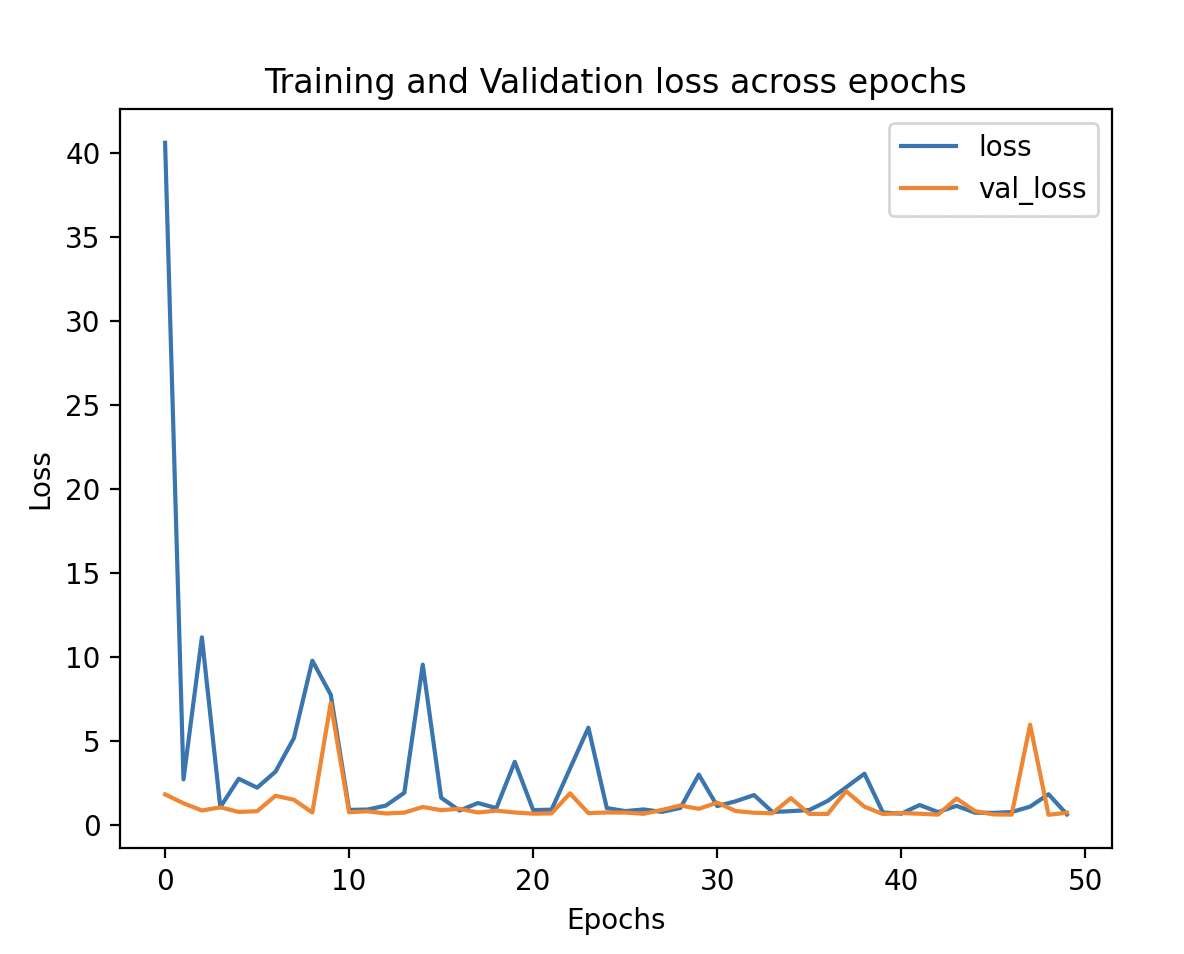
Step 8: Evaluate the Model
model.evaluate(X_val, y_val): Evaluates the model on the validation set.test_loss: The Mean Squared Error on the validation set.test_mae: The Mean Absolute Error on the validation set.
print(f"Validation Mean Absolute Error: {test_mae}"): Prints the validation Mean Absolute Error.
Output and Observations:
Validation Mean Absolute Error for different epochs:
- With 50 epochs, we got a reasonable MAE, which means the model performed well after sufficient training.
- With 10 epochs, the model’s MAE is higher, indicating it was under-trained and did not have enough epochs to learn the underlying patterns.
- With 6 epochs, the model’s error was quite high, indicating it had not trained enough to generalize.
The observation is that training for 50 epochs worked better, as the model had enough time to learn the relationships in the data.