Day 13: Explore Image Segmentation With U-Net on Carvana Dataset
Day 13 brings a deep dive into image segmentation with U-Net, a powerful neural network architecture for segmentation tasks. The Carvana dataset is perfect for this as it involves segmentation of car images, which makes the task visually interesting and a great learning experience.
Let’s break down the task into easy-to-follow parts and help you implement it step by step!
Overview of Image Segmentation and U-Net
-
Image Segmentation: Image segmentation is the process of labeling every pixel in an image such that different parts of the image are identified. For instance, you might want to segment cars from the background so that each pixel belongs to either the car or the background.
-
U-Net: U-Net is a popular convolutional neural network (CNN) used for image segmentation. It is named “U-Net” due to its U-shaped architecture, consisting of:
- Contracting Path: This is like an encoder, where features are extracted and the image resolution decreases.
- Expanding Path: This is like a decoder, where the spatial resolution is gradually restored to produce a segmentation map.
The Carvana dataset is a dataset of car images that come with corresponding masks indicating which parts of the image contain the car, allowing you to train a model to segment cars from their backgrounds.
Steps to Implement U-Net for Car Segmentation
- Set Up Environment and Import Required Libraries
- Load and Preprocess the Dataset
- Build the U-Net Model
- Compile and Train the Model
- Evaluate the Model and Visualize Results
Let’s implement these steps.
Step 1: Set Up Environment and Import Libraries
First, make sure to install the required packages:
pip install tensorflow opencv-python matplotlib Pillow
Then, let’s import the required libraries.
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, MaxPooling2D, UpSampling2D, concatenate, Input
from tensorflow.keras.models import Model
Explanation:
- We use OpenCV for image processing, NumPy for numerical operations, Matplotlib for plotting, and TensorFlow/Keras for building the U-Net model.
- PIL (Pillow) is used to handle image formats, especially for masks in GIF format.
Step 2: Load and Preprocess the Dataset
Here, we will load both the images and their corresponding masks from the dataset folders. We will resize them, normalize them, and make them ready for training.
# Set paths to the dataset folders
IMAGE_DIR = "dataset/carvana/train/" # Path to the train folder
MASK_DIR = "dataset/carvana/train_masks/" # Path to the train_masks folder
def load_data(image_dir, mask_dir, image_size=(128, 128)):
images = []
masks = []
# Load images and masks
for image_name in os.listdir(image_dir):
# Skip hidden files or irrelevant files if any
if image_name.startswith('.'):
continue
# Construct paths to image and corresponding mask
img_path = os.path.join(image_dir, image_name)
# Mask file has "_mask" appended before the extension
base_name = image_name.replace(".jpg", "")
mask_name = f"{base_name}_mask.gif"
mask_path = os.path.join(mask_dir, mask_name)
# Load the image using OpenCV
img = cv2.imread(img_path)
if img is None:
print(f"Warning: Image {img_path} not found or couldn't be loaded.")
continue
img = cv2.resize(img, image_size) / 255.0 # Resize and normalize image to [0, 1]
# Load the mask using PIL (Pillow)
try:
mask = Image.open(mask_path)
mask = mask.convert('L') # Convert to grayscale
mask = np.array(mask) # Convert to numpy array
mask = cv2.resize(mask, image_size) # Resize the mask to the same size as the input image
mask = mask / 255.0 # Normalize to range [0, 1]
mask = np.expand_dims(mask, axis=-1) # Add channel dimension
except Exception as e:
print(f"Warning: Mask {mask_path} not found or couldn't be loaded. Error: {e}")
continue
images.append(img)
masks.append(mask)
return np.array(images), np.array(masks)
# Load the data
X, y = load_data(IMAGE_DIR, MASK_DIR)
print("Dataset loaded successfully.")
print(f"Images shape: {X.shape}, Masks shape: {y.shape}")
# Plot a few images and their corresponding masks
plt.figure(figsize=(12, 6))
for i in range(3):
plt.subplot(2, 3, i + 1)
plt.imshow(X[i])
plt.title("Car Image")
plt.axis('off')
plt.subplot(2, 3, i + 4)
plt.imshow(y[i].squeeze(), cmap='gray')
plt.title("Mask")
plt.axis('off')
plt.tight_layout()
plt.show()

- Training Images are in JPEG format, and masks are in GIF format.
- Masks have filenames that append “_mask” before the file extension.
Explanation:
- Loading Images: Uses OpenCV to read images, resizes them to 128x128, and normalizes them to [0, 1].
- Loading Masks: Uses Pillow to load GIF masks, convert them to grayscale, resize, normalize, and add a channel dimension to make them compatible for training.
Step 3: Build the U-Net Model
The U-Net model has two main parts: a contracting path (encoder) and an expanding path (decoder).
def unet_model(input_size=(128, 128, 3)):
inputs = Input(input_size)
# Contracting Path (Encoder)
c1 = Conv2D(64, (3, 3), activation='relu', padding='same')(inputs)
c1 = Conv2D(64, (3, 3), activation='relu', padding='same')(c1)
p1 = MaxPooling2D((2, 2))(c1)
c2 = Conv2D(128, (3, 3), activation='relu', padding='same')(p1)
c2 = Conv2D(128, (3, 3), activation='relu', padding='same')(c2)
p2 = MaxPooling2D((2, 2))(c2)
c3 = Conv2D(256, (3, 3), activation='relu', padding='same')(p2)
c3 = Conv2D(256, (3, 3), activation='relu', padding='same')(c3)
p3 = MaxPooling2D((2, 2))(c3)
# Bottleneck
c4 = Conv2D(512, (3, 3), activation='relu', padding='same')(p3)
c4 = Conv2D(512, (3, 3), activation='relu', padding='same')(c4)
# Expanding Path (Decoder)
u5 = UpSampling2D((2, 2))(c4)
u5 = concatenate([u5, c3])
c5 = Conv2D(256, (3, 3), activation='relu', padding='same')(u5)
c5 = Conv2D(256, (3, 3), activation='relu', padding='same')(c5)
u6 = UpSampling2D((2, 2))(c5)
u6 = concatenate([u6, c2])
c6 = Conv2D(128, (3, 3), activation='relu', padding='same')(u6)
c6 = Conv2D(128, (3, 3), activation='relu', padding='same')(c6)
u7 = UpSampling2D((2, 2))(c6)
u7 = concatenate([u7, c1])
c7 = Conv2D(64, (3, 3), activation='relu', padding='same')(u7)
c7 = Conv2D(64, (3, 3), activation='relu', padding='same')(c7)
outputs = Conv2D(1, (1, 1), activation='sigmoid')(c7)
model = Model(inputs, outputs)
return model
# Instantiate the model
model = unet_model()
model.summary()
Explanation:
- Contracting Path: Uses
"Conv2D"and"MaxPooling2D"layers to extract features and downsample the image. - Expanding Path: Uses
"UpSampling2D"and"Concatenate"to reconstruct the segmentation map at higher resolution. - outputs: Uses a
"Conv2D"layer with a"1x1"kernel to produce the segmentation mask.
Step 4: Compile and Train the Model
We will use the Adam optimizer and binary cross-entropy loss since this is a binary segmentation task (car vs. background).
# Compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
history = model.fit(X, y, validation_split=0.1, epochs=10, batch_size=8)
Explanation:
"optimizer='adam'": Efficient optimization method for training."loss='binary_crossentropy'": Suitable for binary segmentation."validation_split=0.1": Uses 10% of the data for validation during training.
Step 5: Evaluate the Model and Visualize Results
Finally, we’ll visualize how well the model has learned to segment the cars.
# Select a sample from validation data to predict
sample_image = X[0]
sample_mask = y[0]
# Expand dimensions to make it compatible with model input
sample_image_expanded = np.expand_dims(sample_image, axis=0)
# Predict mask
predicted_mask = model.predict(sample_image_expanded)[0]
# Plot original image, true mask, and predicted mask
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
plt.title("Original Image")
plt.imshow(sample_image)
plt.subplot(1, 3, 2)
plt.title("True Mask")
plt.imshow(sample_mask.squeeze(), cmap='gray')
plt.subplot(1, 3, 3)
plt.title("Predicted Mask")
plt.imshow(predicted_mask.squeeze(), cmap='gray')
plt.show()
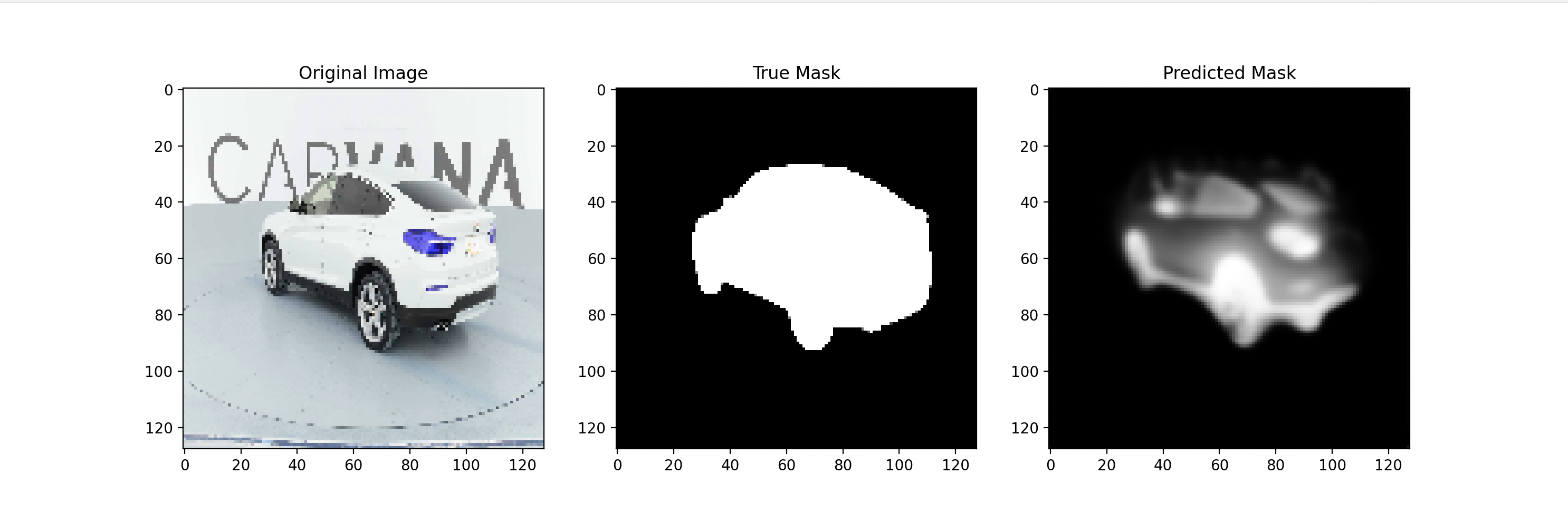
Explanation:
- Prediction: Uses the trained model to predict the mask for a given image.
- Visualization: Compares the original image, true mask, and predicted mask side-by-side for easy evaluation.