Day 15 - 30 Days 30 ML Projects: Predict House Prices With XGBoost
Today’s challenge was to predict house prices using the Ames Housing dataset, a more comprehensive and detailed dataset compared to the simpler California Housing dataset. The task was to build a regression model using XGBoost, a high-performance implementation of gradient boosted decision trees.
If you want to see the code, you can find it here: GIT REPO.
Understanding the Data
We used the Ames Housing Dataset, which contains 80 features describing various aspects of residential properties in Ames, Iowa. These features range from the lot area, year built, and overall quality to more intricate details like basement quality and garage condition.
The target variable in this problem is the SalePrice, representing the selling price of the houses.
Code Workflow
- Load the Data
- Preprocess the Data (Handling Missing Values and Categorical Data)
- Split the Data
- Train the XGBoost Model
- Evaluate the Model
- Visualize Feature Importance
Let’s break down each step.
Step 1: Load the Data
We started by loading the Ames Housing dataset from Kaggle into a pandas DataFrame for easy manipulation and exploration.
import pandas as pd
# Load dataset
data = pd.read_csv('dataset/AmesHousing.csv')
print(data.head())
The dataset contains both categorical and numerical columns, which required different preprocessing approaches.
Step 2: Preprocess the Data
In this step, I handled the missing values and encoded the categorical features. For missing numerical values, I filled them with the median of the respective column, while for categorical data, I filled the missing values with ‘None’.
I used One Hot Encoding to convert categorical features into numerical ones.
# Handle missing values and encode categorical data
for col in data.columns:
if data[col].dtypes in [np.int64, np.float64]:
data[col].fillna(data[col].median(), inplace=True)
else:
data[col].fillna('None', inplace=True)
# One Hot Encoding for categorical features
data_encoded = pd.get_dummies(data, drop_first=True)
# Define feature and target sets
X = data_encoded.drop('SalePrice', axis=1)
y = data_encoded['SalePrice']
Step 3: Split the Data
We split the data into 80% for training and 20% for validation.
from sklearn.model_selection import train_test_split
# Split the data into training and validation sets
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
Step 4: Train the Model
For this problem, I used XGBoost Regressor with 100 estimators and a learning rate of 0.1. XGBoost is ideal for handling large datasets with a mix of numerical and categorical features, offering high performance and accuracy.
from xgboost import XGBRegressor
# Build and train the model
model = XGBRegressor(n_estimators=100, learning_rate=0.1, random_state=42)
model.fit(X_train, y_train)
Step 5: Make Predictions and Evaluate the Model
After training the model, I made predictions on the validation set and calculated the Root Mean Squared Error (RMSE), which helps measure the average error in predicting house prices.
from sklearn.metrics import mean_squared_error
import numpy as np
# Make predictions and evaluate the model
predictions = model.predict(X_val)
mse = mean_squared_error(y_val, predictions)
rmse = np.sqrt(mse)
print("Root Mean Square Error: ", rmse)
Step 6: Visualization
XGBoost has a built-in function for plotting feature importance, which helps understand which features contribute the most to the predictions.
import matplotlib.pyplot as plt
import xgboost
# Plot feature importance
plt.figure(figsize=(7, 5))
xgboost.plot_importance(model, max_num_features=10)
plt.title('Top 10 Important Features')
plt.show()
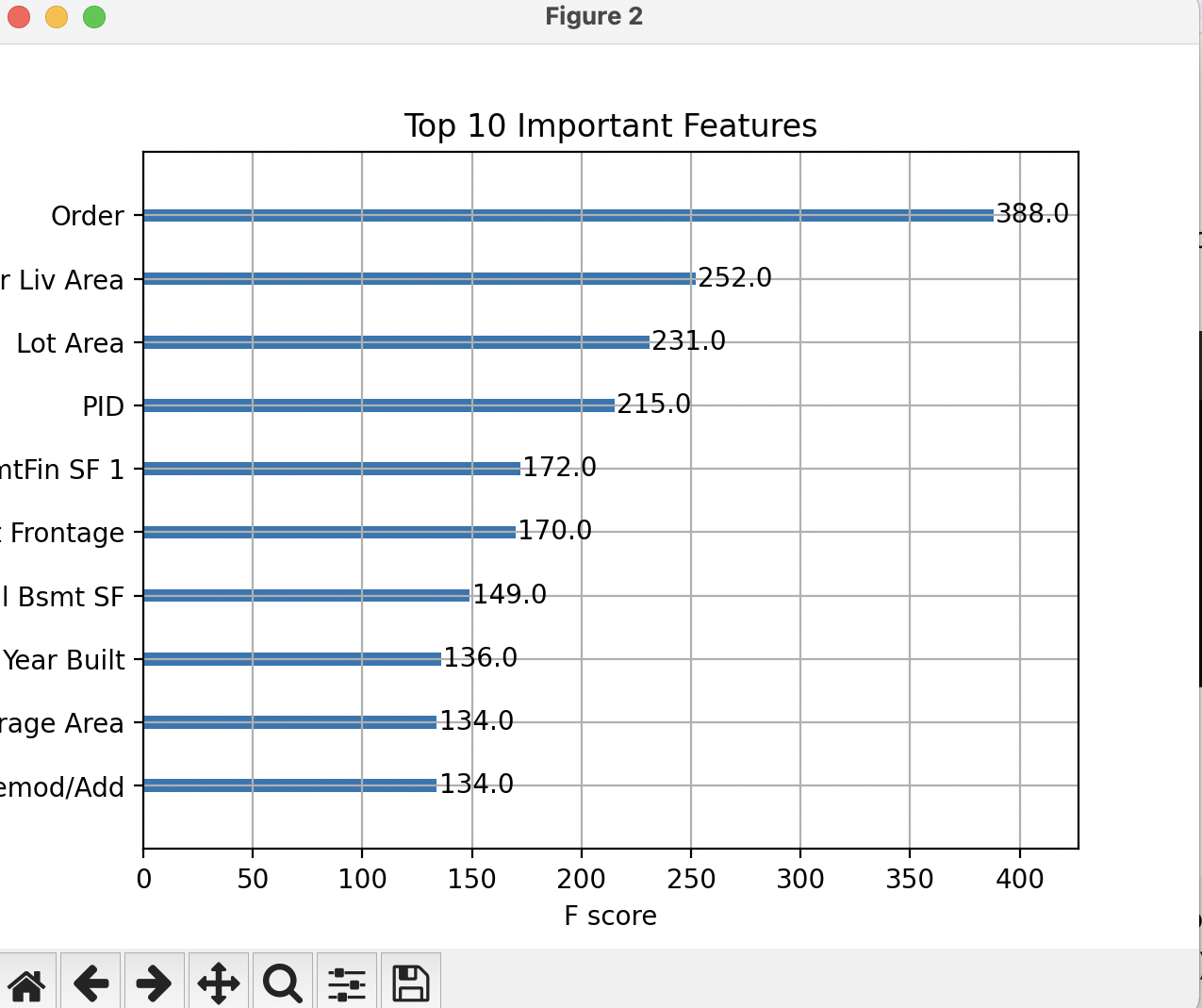
Model Performance
The model performed well, achieving a root mean square error (RMSE) of 24,059.40.
Gratitude
This is the first day of the 3rd week. We explored an advanced model for the same problem we solved on Day 1. I’m excited to continue and complete this challenge.
Stay tuned!