Day 23 - Fraud Detection in Financial Transactions Using Logistic Regression and Random Forest
Today’s challenge involved detecting fraudulent transactions using two machine learning algorithms: Logistic Regression and Random Forest. Fraud detection is critical in the financial world, where minimizing losses from fraudulent transactions is a top priority. This problem posed a unique challenge due to the highly imbalanced dataset, where only a small percentage of transactions are actually fraudulent.
If you want to see the code, you can find it here: GIT REPO.
Dataset:
I used the Credit Card Fraud Detection Dataset from Kaggle, which contains 284,807 transactions, of which only 492 are labeled as fraudulent. The dataset includes numerical features generated through PCA transformations (to protect sensitive information), as well as the feature ‘Class’, which represents whether the transaction is fraudulent (1) or legitimate (0).
Steps Taken:
Let’s import the required libraries first.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
from sklearn.ensemble import RandomForestClassifier
import matplotlib.pyplot as plt
import seaborn as sns
Step 1: Load and Explore the Dataset
I began by loading the dataset and inspecting its structure. The dataset is highly imbalanced, with fraud making up only 0.17% of all transactions. Here’s how I loaded and explored the data:
# Load the dataset
data = pd.read_csv('dataset/creditcard.csv')
print(data.info())
print(data.head())
Step 2: Data Preprocessing
The dataset didn’t contain any missing values, so I could proceed directly to separating the features and the target variable. Given the importance of feature scaling for Logistic Regression, I used StandardScaler to normalize the features.
# Handle missing values.
print(data.isnull().sum())
# We dont have any column with null value.
# Separate features and target
X = data.drop('Class', axis=1) # Features (everything except 'Class')
y = data['Class'] # Target (fraud label: 1 for fraud, 0 for legitimate)
# Split into training and testing datasets
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# Feature scaling
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
Step 3: Logistic Regression
I trained a Logistic Regression model on the scaled data. Logistic Regression is a simple and interpretable model that works well for binary classification tasks.
# Train Logistic Regression model
log_reg_model = LogisticRegression()
log_reg_model.fit(X_train_scaled, y_train)
# Predict on validation data
log_reg_predictions = log_reg_model.predict(X_val_scaled)
# Evaluate the model's performance
log_reg_accuracy = accuracy_score(y_val, log_reg_predictions)
log_reg_conf_matrix = confusion_matrix(y_val, log_reg_predictions)
log_reg_classfication_report = classification_report(y_val, log_reg_predictions)
print(f"Accuracy Score of Logistic Regression: {log_reg_accuracy}")
print(f"Confusion Matrix of Logistic Regression: {log_reg_conf_matrix}")
print(f"Classification Report of Logistic Regression: {log_reg_classfication_report}")
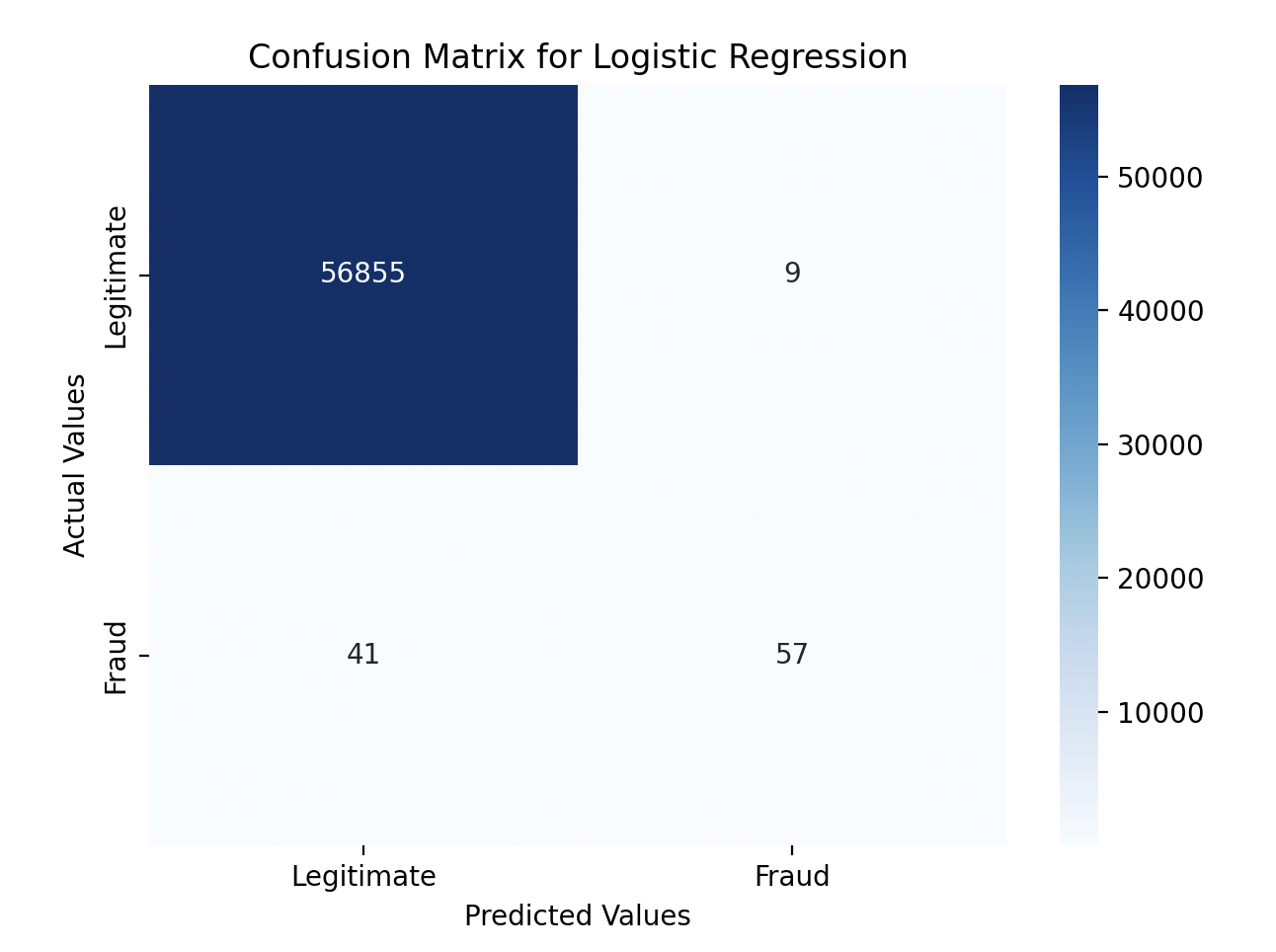
Logistic Regression Results:
- Accuracy: The model achieved an accuracy score of 0.999, which indicates that most transactions were classified correctly.
- Precision and Recall: While the precision for fraud detection was strong, the recall was somewhat lower, meaning the model struggled to identify all fraudulent transactions.
- Confusion Matrix: The confusion matrix highlighted that out of 98 fraudulent transactions, 41 were missed.
Step 4: Random Forest
Next, I trained a Random Forest classifier, which is a more powerful model, well-suited to handling the complexity of this dataset and the class imbalance.
# Train Random Forest model
ran_for_model = RandomForestClassifier(random_state=42)
ran_for_model.fit(X_train, y_train)
# Predict on validation data
ran_for_predictions = ran_for_model.predict(X_val)
# Evaluate the model's performance
ran_for_accuracy = accuracy_score(y_val, ran_for_predictions)
ran_for_conf_matrix = confusion_matrix(y_val, ran_for_predictions)
ran_for_classfication_report = classification_report(y_val, ran_for_predictions)
print(f"Accuracy Score of Random Forest: {ran_for_accuracy}")
print(f"Confusion Matrix of Random Forest: {ran_for_conf_matrix}")
print(f"Classification Report of Random Forest: {ran_for_classfication_report}")
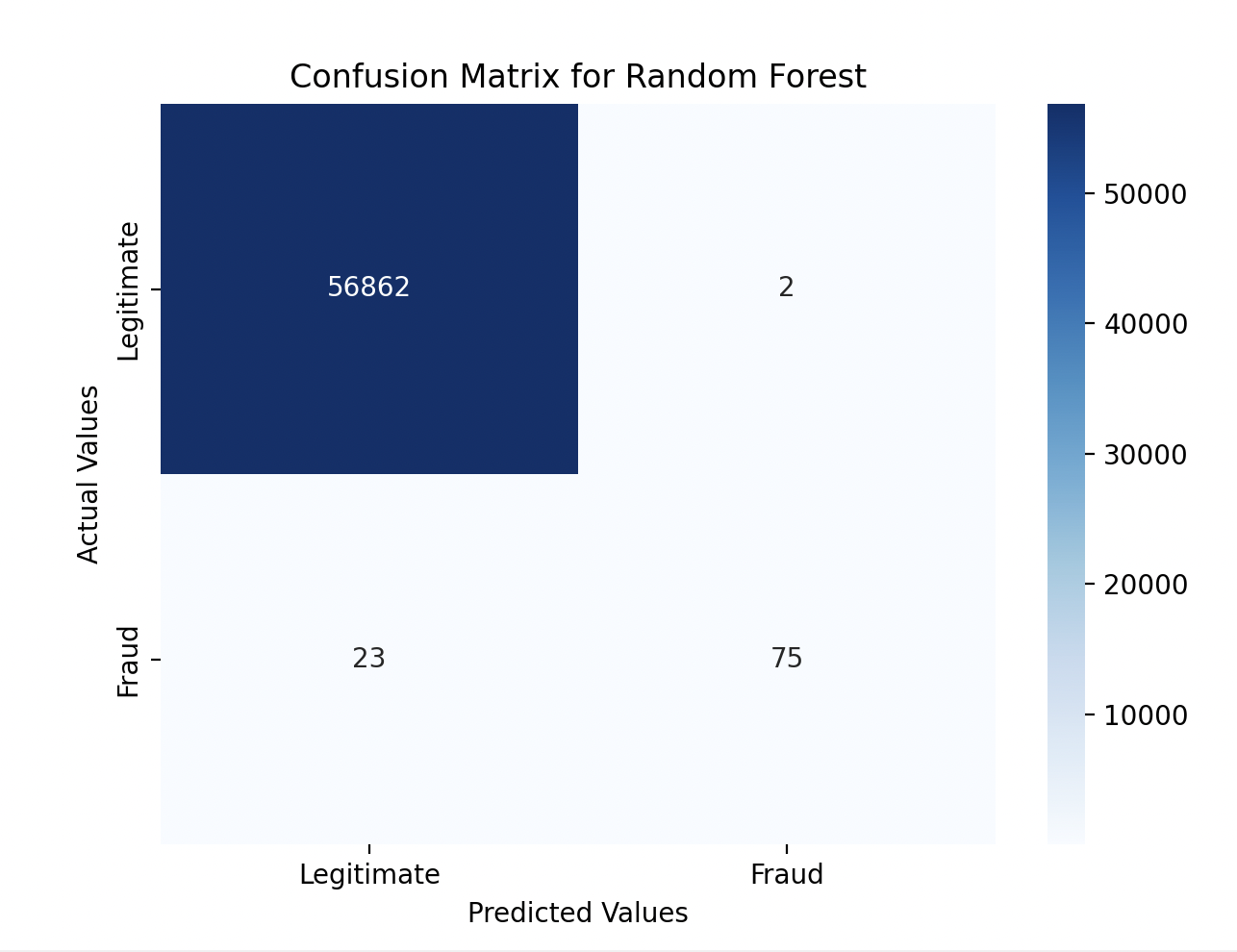
Random Forest Results:
- Accuracy: The Random Forest model achieved a slightly higher accuracy score of 0.9995.
- Precision and Recall: The model showed excellent precision and recall, significantly improving its ability to detect fraudulent transactions. The recall was much higher than in Logistic Regression, meaning it identified most of the fraud cases.
- Confusion Matrix: The Random Forest model missed fewer fraud cases compared to Logistic Regression, with only 23 false negatives out of 98 fraud cases.
Step 5: Visualizing Results
Finally, I visualized the confusion matrices for both models using Seaborn, which helped me better understand how the models were performing in classifying fraudulent and legitimate transactions.
# Confusion Matrix for Logistic Regression
plt.figure(figsize=(7, 5))
sns.heatmap(log_reg_conf_matrix, annot=True, fmt='d', cmap='Blues', xticklabels=['Legitimate', 'Fraud'], yticklabels=['Legitimate', 'Fraud'])
plt.xlabel('Predicted Values')
plt.ylabel('Actual Values')
plt.title('Confusion Matrix for Logistic Regression')
plt.show()
# Confusion Matrix for Random Forest
plt.figure(figsize=(7, 5))
sns.heatmap(ran_for_conf_matrix, annot=True, fmt='d', cmap='Blues', xticklabels=['Legitimate', 'Fraud'], yticklabels=['Legitimate', 'Fraud'])
plt.xlabel('Predicted Values')
plt.ylabel('Actual Values')
plt.title('Confusion Matrix for Random Forest')
plt.show()
Results:
Logistic Regression:
- Accuracy: 99.91%
- Precision: 0.86 for fraud detection
- Recall: 0.58 (The model missed 41 fraud cases out of 98)
Key Takeaway: While Logistic Regression performed well overall, it struggled to catch all fraud cases, especially in such an imbalanced dataset.
Random Forest:
- Accuracy: 99.96%
- Precision: 0.97 for fraud detection
- Recall: 0.77 (The model missed only 23 fraud cases out of 98)
Key Takeaway: Random Forest performed significantly better in identifying fraudulent transactions, especially in terms of recall, which is critical in fraud detection.
Confusion Matrix
The confusion matrices provided visual insight into how the models classified transactions. Random Forest was much better at reducing false negatives (missed fraud cases) compared to Logistic Regression.
Gratitude
We saw that:
- Logistic Regression: A simple, interpretable model, but it struggled with imbalanced data, missing a number of fraud cases.
- Random Forest: A more powerful model that excelled at detecting fraud, even in a highly imbalanced dataset. Its higher recall meant it was better suited to fraud detection where identifying all fraud cases is crucial.
Stay Tuned!