Day 8 - 30 Days 30 Machine Learning Projects
Hey, it’s Day 8 of the 30 Day 30 Machine Learning Projects Challenge. Today’s task was to build a model to detect fake news using a PassiveAggressive Classifier and TfidfVectorizer. Let’s go step-by-step to see how we used machine learning to classify news articles as real or fake.
If you want to see the code, you can find it here: GIT REPO.
The Problem
The challenge today was to automatically detect fake news by analyzing the content of news articles. The model should predict whether a news article is real or fake.
Understanding the Data
We used the Fake News Detection Datasets Dataset from Kaggle, It contains two datasets: True.csv (real news) and Fake.csv (fake news). Each file contains columns like title, text, subject, and date. In this project, we used the text column to help the model decide if the news is real or fake. Unzip and put it in the dataset directory at the root level of your project.
Code Workflow
- Load the data
- Prepare the data
- Preprocess the data: Create feature and target datasets
- Convert the text data into numerical form using TfidfVectorizer
- Split the data
- Built and train model
- Made predictions and evaluate
- Visualization
Step 1: Load the Data
We first loaded the True.csv and Fake.csv datasets using pandas:
fake_df = pd.read_csv('dataset/Fake.csv')
true_df = pd.read_csv('dataset/True.csv')
Step 2: Prepare the data
I labeled the real news as 1 and the fake news as 0. Then, I combined both datasets into one:
fake_df['label'] = 0 # Label 0 is for Fake news
true_df['label'] = 1 # Label 1 is for True news
df = pd.concat([true_df, fake_df], axis=0).reset_index(drop=True)
Step 3: Preprocess the data
I then separated the data into Features (X) and Target (y) datasets.
X = df['text'] # Feature
y = df['label'] # Target
Step 4: Convert the text data into numerical form using TfidfVectorizer
To convert the text data into a format that a machine learning model can understand, I used TfidfVectorizer. This method gives weight to words based on how important and unique they are in the dataset.
tf_idf_vectorizer = TfidfVectorizer(stop_words="english", max_df=0.7) # Ignore if the words appears in 70% or more of the documents.
X_tf_idf = tf_idf_vectorizer.fit_transform(X)
Let’s understand TfidfVectorizer in depth:
How Does TfidfVectorizer Work?
TfidfVectorizer stands for Term Frequency-Inverse Document Frequency Vectorizer. It’s a method of converting textual data (like news articles, emails, or any text) into numerical form (a matrix of numbers) that machine learning algorithms, such as the PassiveAggressiveClassifier, can work with.
It combines two key ideas:
Term Frequency (TF): Measures how often a word appears in a document.
TF(t,d) = Number of times term t appears in document d / Total number of terms in document d
Example: If the word “news” appears 5 times in a 100-word document, its TF is:
TF("news",d) = 5 / 100 = 0.05
Inverse Document Frequency (IDF): Measures how important a word is across all documents. Common words like “the” get lower scores.
IDF(t)=log( Total number of documents /Number of documents containing the term t )
Words that appear in fewer documents get a higher IDF score.
How Does TfidfVectorizer Help?
TfidfVectorizer creates a matrix where:
- Rows represent documents (news articles).
- Columns represent words.
- Values are the TF-IDF scores, which highlight important words like “fraud” or “scandal” and reduce the impact of common words like “the”.
How Does TfidfVectorizer Help the PassiveAggressiveClassifier?
The PassiveAggressiveClassifier uses these TF-IDF scores to detect fake news:
- Passive: The model doesn’t change if it predicts correctly.
- Aggressive: It updates itself when it makes a mistake to improve future predictions.
TF-IDF ensures important words get more attention, helping the classifier focus on key features to decide if the news is fake or real.
Step 5: Split the Data
We divided the data into an 80-20 ratio: training (80%) and validation (20%) sets using:
X_train, X_val, y_train, y_val = train_test_split(X_tf_idf, y, test_size=0.2, random_state=42)
Here, random_state=42 sets the seed for randomness. This ensures the same split occurs on every run. The number 42 is commonly used but has no special meaning.
Step 6: Build and Train the Model
I used a PassiveAggressiveClassifier for this task. This model is efficient and updates itself quickly when it makes mistakes, which is why it’s great for real-time detection tasks like fake news.
model = PassiveAggressiveClassifier(max_iter=10)
model.fit(X_train, y_train)
Step 7: Make Predictions and Evaluate
Once the model was trained, I tested it on the validation data and evaluated how well it performed. Here’s how I checked the accuracy, confusion matrix, and classification report:
predictions = model.predict(X_val)
accuracy_score = accuracy_score(y_val, predictions)
print("Accuracy score:\n", accuracy_score)
confusion_matrix = confusion_matrix(y_val, predictions)
print("Confusion Matrix:\n", confusion_matrix)
classification_report = classification_report(y_val, predictions)
print("Classification Report:\n", classification_report)
Step 8: Visualization
Finally, I created a heatmap to visualize the confusion matrix, which helps us see how well the model predicted real and fake news:
plt.figure(figsize=(7,5))
sns.heatmap(confusion_matrix, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted Values')
plt.ylabel('Actual Values')
plt.title('Confusion Matrix')
plt.show()
Model Performance
The model achieved an accuracy of 93%, which is a strong result for detecting fake news. Here’s how the model performed:
- True Positives (TP): Correctly predicted real news are 4302.
- True Negatives (TN): Correctly predicted fake news are 4623.
- False Positives (FP): Predicted fake news as real are 27.
- False Negatives (FN): Predicted real news as fake are 28.
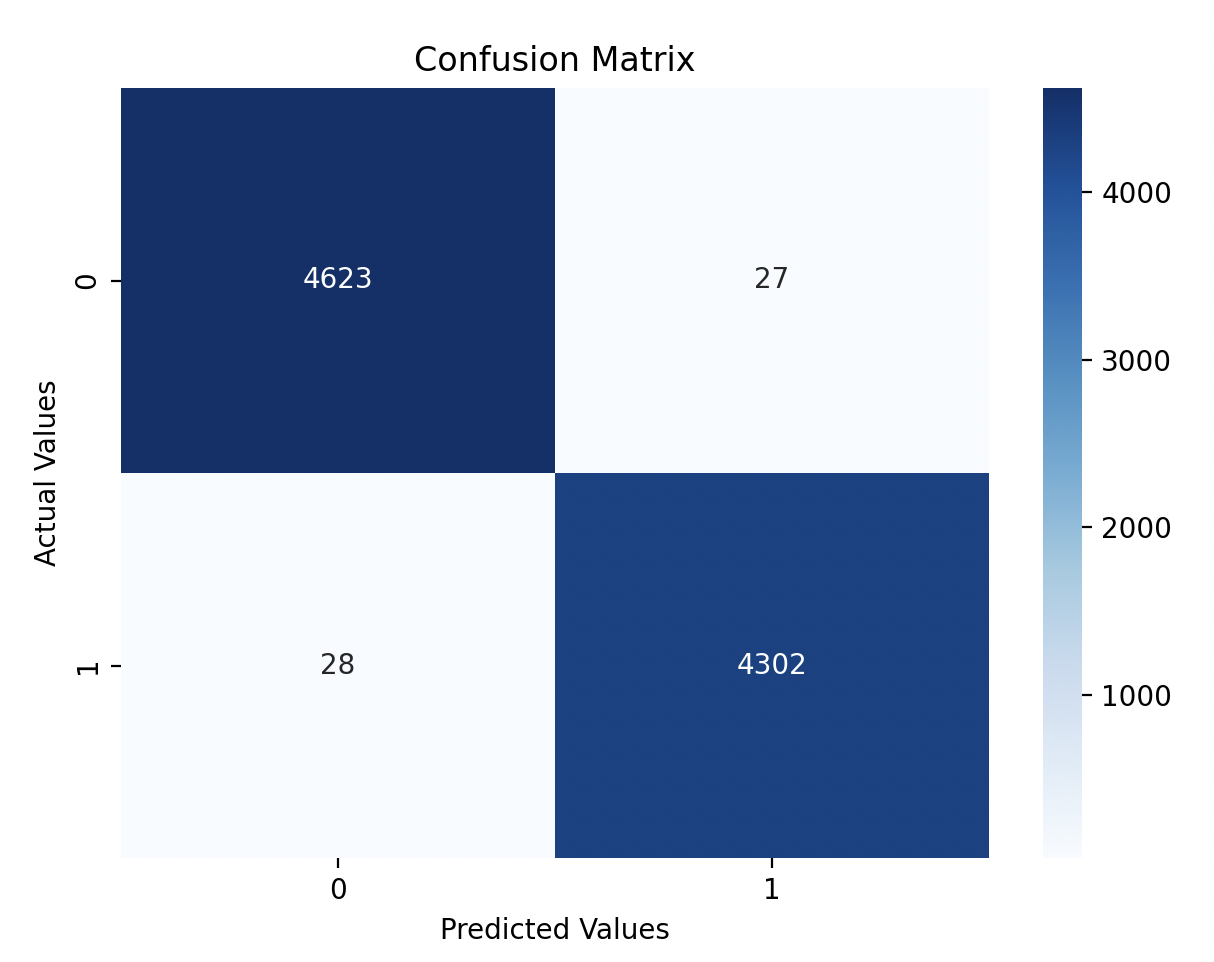
Here’s the classification report:
Classfication Report:
precision recall f1-score support
0 0.99 0.99 0.99 4650
1 0.99 0.99 0.99 4330
accuracy 0.99 8980
macro avg 0.99 0.99 0.99 8980
weighted avg 0.99 0.99 0.99 8980
Gratitude
This was another fun and informative project in the challenge! I’m looking forward to tackling more problems and improving my machine learning skills.
Stay tuned!