DocuMentor: Build a RAG Chatbot With Ollama, Chroma & Streamlit
In this article, we build a Retrieval-Augmented Generation (RAG) web application called DocuMentor that allows users to upload PDF documents and ask questions about the contents.
Let’s understand this with the help of a real-world example.
Let’s say you have a web app for your hospital that contains extensive data about doctors—their names, departments, phone numbers, working hours, and more. Now you want to build a chatbot like ChatGPT, but it should address specific queries about your data, such as the details of doctors working at your hospital.
Here’s how it would look:
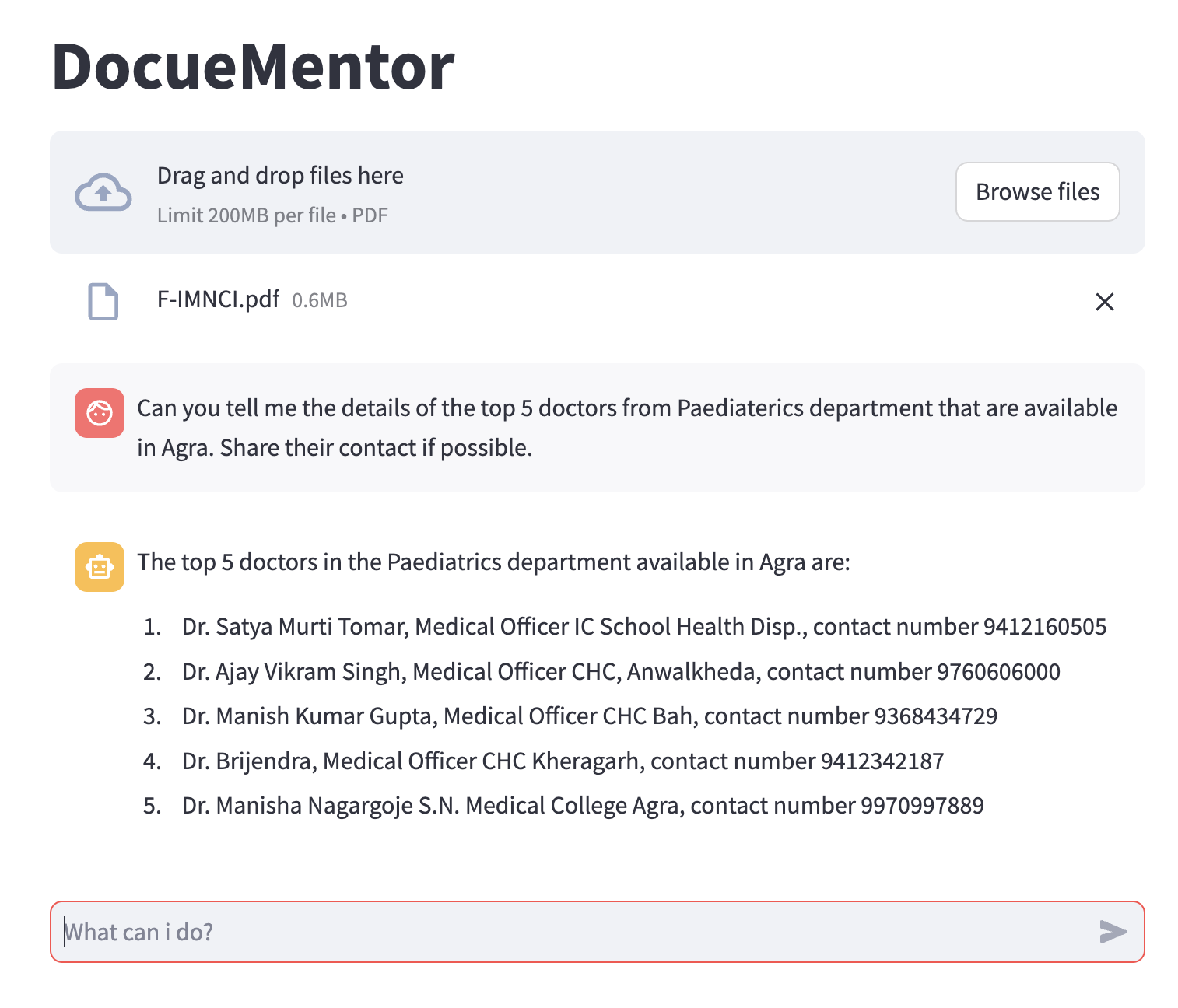
Note: I have used a PDF that is publicly available on the official website of the Uttar Pradesh National Health Mission.
Without wasting any more time, let’s get started.
Dependencies
- langchain
- streamlit
- streamlit_chat
- pypdf
- chromadb
- fastembed
pip install langchain langchain_community streamlit streamlit_chat chromadb pypdf fastembed
Tech stack used:
We will use
- Ollama for running the LLMs locally. If you want to learn more about Ollama and how to get started with it locally, visit this article first.
- Lllama Model mistral: Use
ollama listto check if it is installed on your system, or else use the commandollama pull mistralto download the latest default manifest of the model. - Chroma vector database to store the PDF document’s vector embeddings.
- Streamlit to build the UI of the application.
If the jargon used here sounds alien to you, I recommend referring to the following blogs to understand the RAG concept and learn how to build a RAG application from scratch without any external vector database.
- Retrieval Augmented Generation (RAG): A Beginner’s Guide to This Complex Architecture.
- Song Recommender: Building a RAG Application for Beginners From Scratch
Full Code
The full code of the application is available on the Git repository https://github.com/saxenaakansha30/documentor
Let’s Code
We will have 3 files.
- main.py: Implements UI of the app.
- rag.py: Implements retrieval, augmentation and response generation.
- chunk_vector_store.py: Implements class to split PDF into chunks and provide vector store.
File main.py
import streamlit as st
import tempfile
import os
# Import Rag classes.
from rag import Rag
#Display all messages stored in session_state
def display_messages():
for message in st.session_state.messages:
with st.chat_message(message['role']):
st.markdown(message['content'])
def process_file():
st.session_state["assistant"].clear()
st.session_state.messages = []
for file in st.session_state["file_uploader"]:
# Store the file at tem location
# of your system to feed to our vector storage.
with tempfile.NamedTemporaryFile(delete=False) as tf:
tf.write(file.getbuffer())
file_path = tf.name
#feed the file to the vector storage.
with st.session_state["feeder_spinner"], st.spinner("Uploading the file"):
st.session_state["assistant"].feed(file_path)
os.remove(file_path)
def process_input():
# See if user has typed in any message and assign to prompt.
if prompt := st.chat_input("What can i do?"):
with st.chat_message("user"):
st.markdown(prompt)
st.session_state.messages.append({"role": "user", "content": prompt})
# Generate response and write back to the chat container.
response = st.session_state["assistant"].ask(prompt)
with st.chat_message("assistant"):
st.markdown(response)
st.session_state.messages.append({"role": "assistant", "content": response})
def main():
st.title("DocueMentor")
# Initialize the session_state.
if len(st.session_state) == 0:
st.session_state["assistant"] = Rag()
st.session_state.messages = []
# Code for file upload functionality.
st.file_uploader(
"Upload the document",
type = ["pdf"],
key = "file_uploader",
on_change=process_file,
label_visibility="collapsed",
accept_multiple_files=True,
)
st.session_state["feeder_spinner"] = st.empty()
display_messages()
process_input()
if __name__ == "__main__":
main()
Streamlit’s official documentation explains very nicely how to build a chatbot UI. Refer to the article Build chatbot UI using streamlit
We have two important functions: feed(file_path) and ask(prompt). The feed function is used to feed the PDF file into our Chroma database, and ask is the callback to the user_input. It returns a response by first retrieving the context from the PDF with the maximum similarity stored in the Chroma vector database, then asking the Mistral LLM for a response with this additional context.
File rag.py implements class Rag
from chunk_vector_store import ChunkVectorStore as cvs
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser
from langchain.prompts import PromptTemplate
from langchain_community.chat_models import ChatOllama
class Rag:
vector_store = None
retriever = None
chain = None
def __init__(self) -> None:
self.csv_obj = cvs()
self.prompt = PromptTemplate.from_template(
"""
<s> [INST] You are an assistant for question-answering tasks. Use the following pieces of retrieved context
to answer the question. If you don't know the answer, just say that you don't know. Use three sentences
maximum and keep the answer concise. [/INST] </s>
[INST] Question: {question}
Context: {context}
Answer: [/INST]
"""
)
self.model = ChatOllama(model="mistral")
def set_retriever(self):
self.retriever = self.vector_store.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={
"k": 3,
"score_threshold": 0.5,
},
)
# Augment the context to original prompt.
def augment(self):
self.chain = ({"context": self.retriever, "question": RunnablePassthrough()}
| self.prompt
| self.model
| StrOutputParser())
# Generate the response.
def ask(self, query: str):
if not self.chain:
return "Please upload a PDF file for context"
return self.chain.invoke(query)
# Stores the file into vector database.
def feed(self, file_path: str):
chunks = self.csv_obj.split_into_chunks(file_path)
self.vector_store = self.csv_obj.store_to_vector_database(chunks)
self.set_retriever()
self.augment()
def clear(self):
self.vector_store = None
self.chain = None
self.retriever = None
chunk_vector_store file implementing ChunkVectorStore class
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores.utils import filter_complex_metadata
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores import chroma;
from langchain_community.embeddings import fastembed;
class ChunkVectorStore:
def __init__(self) -> None:
pass
def split_into_chunks(self, file_path: str):
doc = PyPDFLoader(file_path).load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=20)
chunks = text_splitter.split_documents(doc)
chunks = filter_complex_metadata(chunks)
return chunks
def store_to_vector_database(self, chunks):
return chroma.Chroma.from_documents(documents=chunks, embedding=fastembed.FastEmbedEmbeddings())
We use 3 public and 3 local class variables. Let’s understand them:
- vector_store: is a Chroma vector database object initialized with chunks and the type of embedding used to convert those chunks.
- retriever: An object of vector_store used as retriever. It retrieves the top 3 elements with a similarity threshold >= 0.5 using the similarity_score_threshold search technique.
- csv_obj: Object of the ChunkVectorStore class.
- prompt: A prompt template to be filled later with context and question using the Python chaining technique.
- model: Object for invoking the Mistral LLM model.
- chain: Used for chaining.

In summary,
When a user uploads a PDF document, process_file() in main.py is triggered. It uploads the file to the system’s temporary location using the tempfile module. The file path is then passed to the feed() method of the Rag class, stored as an object in Streamlit’s session_state[“assistant”].
feed() uses:
ChunkVectorStoreto split the PDF into chunks of size 1024 bytes usingRecursiveCharacterTextSplitter.- It then calls
ChunkVectorStore.store_to_vector_database()to create and the return vector_store - The vector store is then set as a retriever by calling the function Rag.set_retriever().
- Once the retriever is ready, we prepare the prompt template by calling Rag.augment().
When a user asks a question, it’s passed to the ask() method of the Rag class. The function checks if the retriever is set, along with other variables, by using a chaining technique stored in the variable chain. If everything is configured, it invokes the Mistral model with the prompt and context and returns the response.
Congratulations! We have successfully built a functional RAG application.
Video Explaination
If you want video version of this content, check out this video.
Posts in this series
- Inside the Codebase: A Deep Dive Into Drupal Rag Integration
- Build Smart Drupal Chatbots With RAG Integration and Ollama
- DocuMentor: Build a RAG Chatbot With Ollama, Chroma & Streamlit
- Song Recommender: Building a RAG Application for Beginners From Scratch
- Retrieval Augmented Generation (RAG): A Beginner’s Guide to This Complex Architecture.