A Practical Framework for Writing Effective Prompts
I spent last week reading various resources, ranging from official documentation from Anthropic, OpenAI, and Microsoft, to Harvard’s blog and the Prompt Engineering Guide by DAIR.AI, and I started to see a pattern. Interacting with Large Language Models (LLMs) isn’t just about asking questions; it’s about providing a structured input that predictably yields a desired output. It’s less like a conversation and more like a well-formed API call.
For anyone in the tech space looking to get more out of these models, the quality of your output is a direct function of the quality of your input. Here, I’ve converted my learnings into a practical framework, moving from basic commands to more advanced mental models for tackling complex tasks.
Pro Tip: This pattern can be applied to any field, not just development.
Level 1: The Default Approach: Zero-Shot Prompting
Most interactions with an LLM start here. A Zero-Shot Prompt is essentially a direct command without any prior context or examples. You ask for something and trust the model’s pre-trained knowledge to figure it out.
A typical Zero-Shot prompt:
Generate a Python function that calculates the factorial of a number.
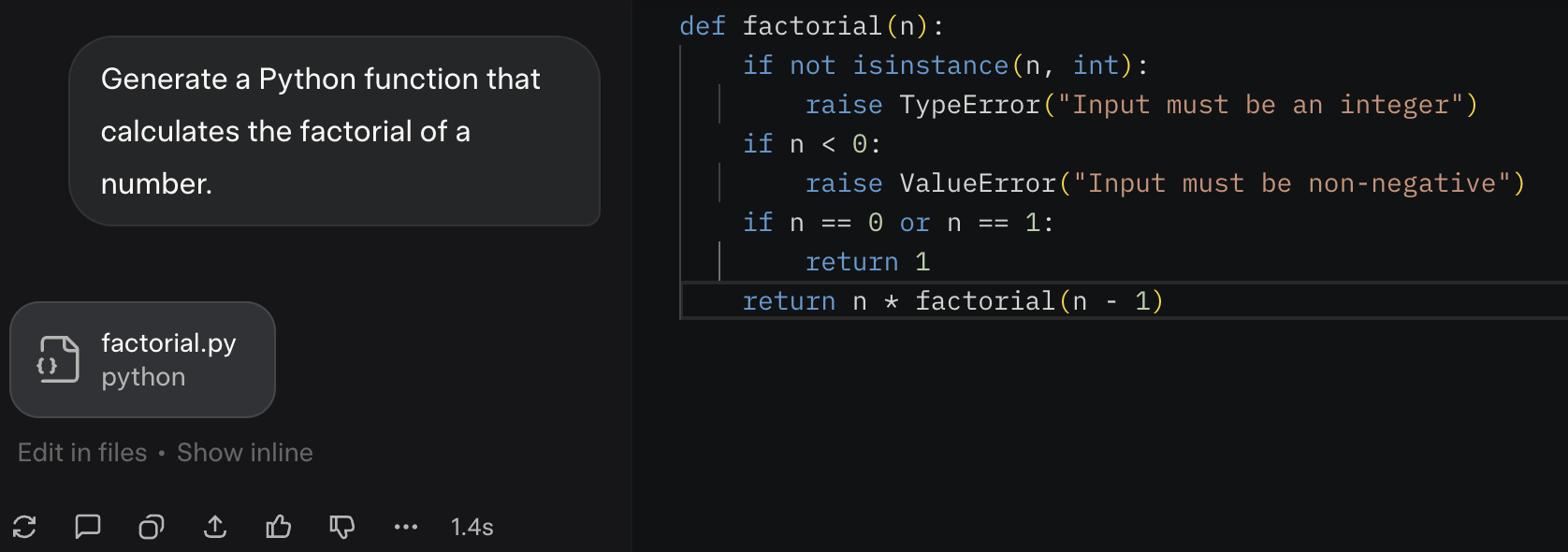
Zero-shot prompt output screenshot (click to enlarge)
The model produced a correct function. But for anything more specific, like requiring a specific style, error handling, or documentation, this approach is a pure hit-n-trail. The output is functional but unrefined because the instruction lacked specificity.
Level 2: The Practical Upgrade: Structured, Example-Driven Prompting
To get reliable and high-quality results, we need to provide the model with a better specification. This involves two key upgrades: providing a structured brief and giving it an example to follow.
1. The Structured Brief (The C-R-A-F-T Framework)
I’ve found it useful to structure my prompts using a mental model I call C-R-A-F-T. It ensures I provide all the necessary parameters for the “API call” to the LLM.
- C - Context: The background and scope of the task.
- R - Role: The persona the model should adopt (e.g., “Act as a senior software architect”).
- A - Action: The specific verb for the task (e.g., “Refactor,” “Generate,” “Summarize,” “Analyze”).
- F - Format: The desired output structure (e.g., “JSON format,” “a markdown table,” “a bulleted list”).
- T - Target: The intended audience for the output.
2. Example-Driven Guidance (Few-Shot Prompting)
A Few-Shot Prompt is the most effective way to guide the model’s output style. By providing one or more examples, you give the model a concrete pattern to replicate.
Putting it all together for a technical task:
(Role) Act as a Python developer specializing in clean, readable code. (Context) I am writing a utility script and need a function to fetch data from a public API. (Action) Write a Python function that takes a URL as an argument and returns the JSON response. (Format) The function must include a docstring explaining its purpose, parameters, and return value. It should also include basic error handling for network requests.
(Few-Shot Example) Here is an example of my preferred coding style:
def add(a: int, b: int) -> int: """Adds two integers together. Args: a: The first integer. b: The second integer. Returns: The sum of the two integers. """ return a + b
This combined approach moves from a vague request to a precise specification. The resulting code will not only be functional but will also match your required standards for documentation and structure.
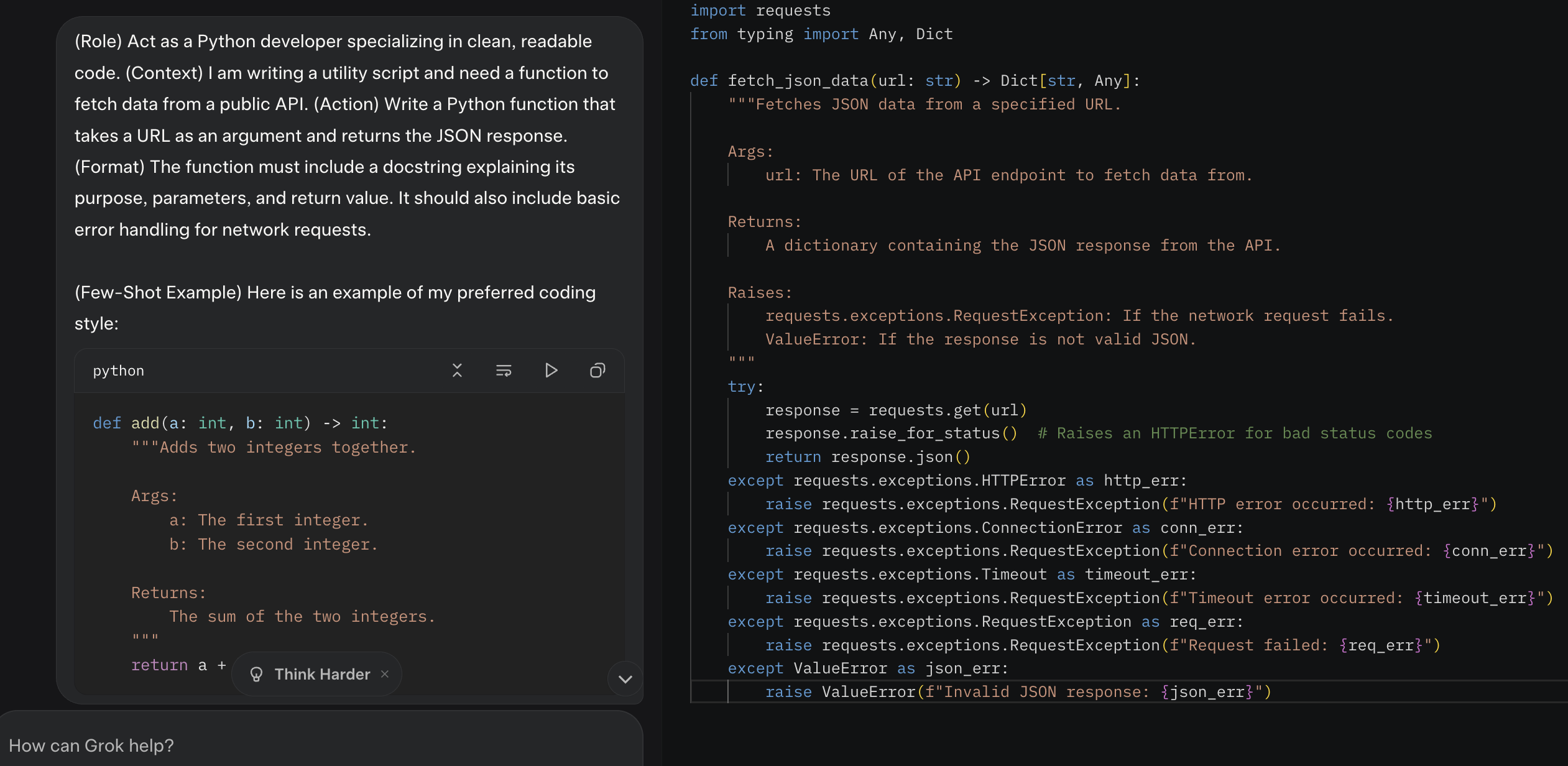
C-R-A-F-T + Few-Shot prompt output screenshot (click to enlarge)
Level 3: Advanced Mental Models for Complex Tasks
For tasks that require reasoning or creativity, we need to guide the model’s “thought process.”
For Logical Reasoning: Chain of Thought (CoT)
When a task involves multiple steps, you can use Chain of Thought (CoT) prompting by simply instructing the model to “think step-by-step.” This forces it to externalize its reasoning process, which often leads to more accurate and logical conclusions. It’s the difference between asking for a final answer and asking the model to show its work, the latter is better right? Let’s understand with the help of an example:
The Goal: Debug a complex configuration issue.
First, the vague prompt that gives a less helpful answer:
Why is my Docker container failing to connect to the database?
Now, the far more effective Chain of Thought prompt:
I’m debugging a Docker networking issue. My application container can’t connect to my database container. Thinking step-by-step, list the potential causes and suggest a command to verify each one.
This prompt yields a structured, actionable checklist instead of a single guess.

Chain of thought prompt output screenshot (click to enlarge)
For Strategic Exploration: Tree of Thought (ToT)
For tasks where there isn’t one right answer, like system design or technical strategy, the Tree of Thought (ToT) model is incredibly powerful. You guide the LLM to explore multiple independent lines of reasoning (“branches”), evaluate their pros and cons, and then synthesize a final recommendation.
The Goal: Choose a database for a new application.
Tree of Thought Prompt:
Act as a senior software architect. I am designing a new social media application.
- First, propose three different database options: one SQL, one NoSQL (Document), and one NoSQL (Graph).
- Next, for each option, briefly analyze its pros and cons specifically for a social media application’s data model (e.g., user profiles, posts, social connections).
- Finally, conclude with a recommendation for which database to start with and provide a brief justification.
This approach moves the LLM from being a simple information retriever to a powerful analysis and reasoning partner.
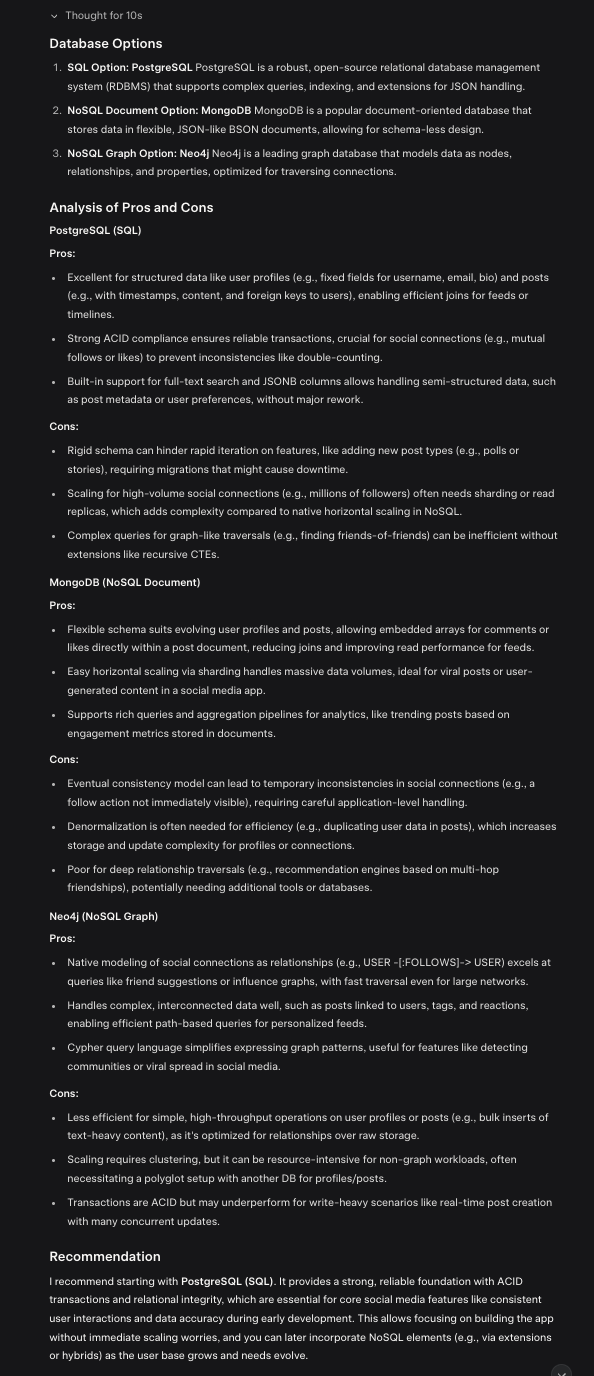
Tree of thought prompt output screenshot (click to enlarge)
Cheat Sheet
| Technique | Primary Use Case |
|---|---|
| Zero-Shot | Quick idea generation and baseline outputs. |
| C-R-A-F-T + Few-Shot | Creating high quality, structured content that matches a specific style. |
| Chain of Thought (CoT) | Solving logical problems, debugging, and creating step-by-step plans. |
| Tree of Thought (ToT) | Brainstorming multiple strategies, exploring creative paths, and receiving a final recommendation. |
Final Takeaway
My biggest takeaway from this journey is that the real skill lies in moving from simply ‘prompting’ to actual ’engineering’. Treating my interactions with an LLM less like a conversation and more like a well-structured API call was the mental shift that made everything click.
The better the spec, the better the output. It’s a principle every developer already understands, just applied to a new and powerful context. The initial effort to be more structured is what turns a fascinating tool into a truly reliable one.