Retrieval Augmented Generation (RAG): A Beginner’s Guide to This Complex Architecture.
RAG, or Retrieval Augmented Generation, is getting a lot of talk these days. It’s pretty exciting, but also a bit confusing for beginners. In this article I attempt to explain RAG in a way that’s easier to understand, without all the complex tech words.
What is RAG?
RAG stands for Retrieval Augmented Generation, an architecture that lets you feed your own content to a generic Large Language Model (LLM) to generate relevant responses.
Think of the following scenarios:
Example 1: Easy to understand example:
You have to write an essay on History of India. The first thing you do is to use search engine to look up the information. You find the links to the articles/documentation that contain the information you need and then you write the essay in your own words based of that information.
Rag works in the same way. It is divided into two components. Retriever and Generation. So if I categorise the essay example into Retriever and Generation.
The job of Retriever is to get relevant content from the internet in the form of articles/document. And Generation will be to use it to write essay in your own words.

Example 2: A little technical use case.
You have a support system and you are thinking of using LLM to create a chatbot to help with the questions and answer. Now let’s see how this bot works with or without RAG.
A user comes and asks- I am seeing a white screen of death on this page. How do I resolve it. LLM response: A generic response. Might or might be related to your system.
Chatbot before RAG:
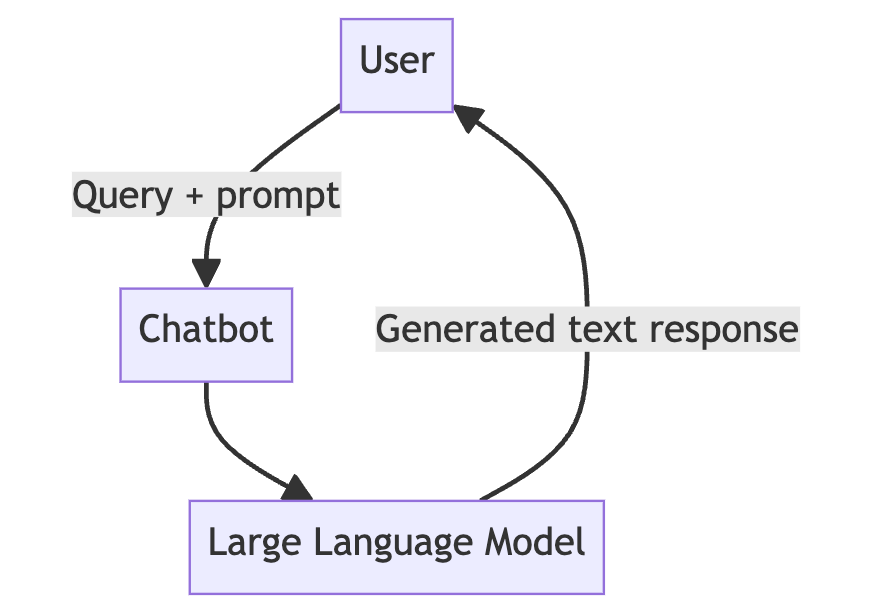
With RAG:
You can use your content to provide relevant response around your system to the user. You can use old solutions as the data.
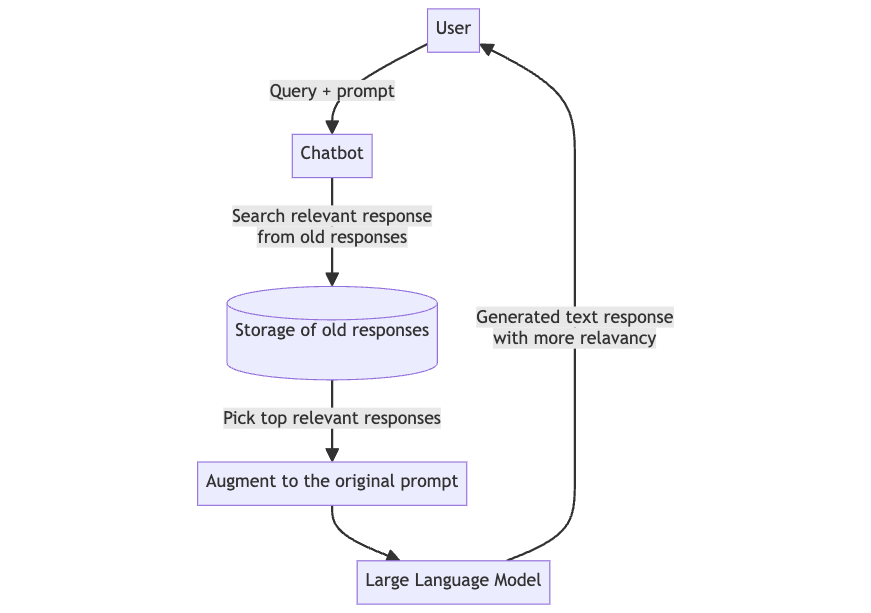
User —> Old Response —> Augment to the original Prompt -> LLM
Benefits:
- Improved Accuracy with factually correct responses to queries.
- Avoid hallucinations or irrelevant responses
- Access to up-to-date information and reduced data training times since RAG models aren’t limited to the data they were initially trained on
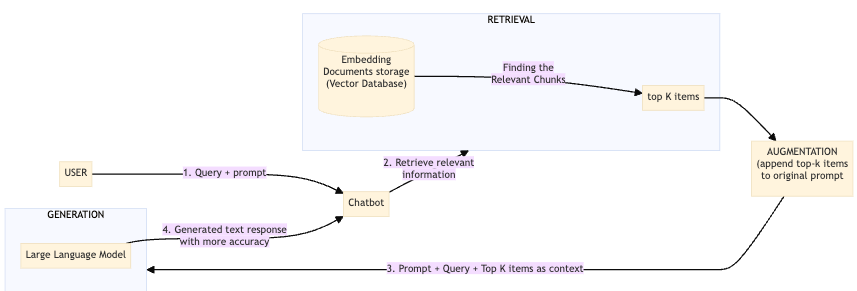
How does it work:
User: User sends the prompt or can say ask a question.
Retrieval:
It is a process of finding relevant information from a large dataset that can help in generating accurate responses to queries. This is typically achieved through the following process:
Indexing Knowledge: Split the data in small chunks. Depending on the nature of the data, this could mean splitting up long articles into paragraphs or sections, so each piece can be independently assessed for its relevance to a query.
Transforming Text into Numeric Codes (Embedding Documents): We take each section of text and turn it into ’embeddings’ or numeric codes (vectors). This process is like giving each chunk its own unique number that reflects what the words are about."
Store the Embeddings: Save this embeddings into a special database called vector database like chromes[LINK]
Embedding the Query: Convert the query to embedding using the same method.
Finding the Relevant Chunks: With both documents and the query turned into vectors, the retrieval system performs a search to identify which document embeddings are closest to the query embedding.
Selection the information to use: Select top K items from the list that are most relevant to the query.
Augmentation:
Append the information as context to the original prompt and pass it to the LLM.
Generation:
Generic LLM uses the prompt (original user query with relevant information) and generates the response.
Hope this article has helped you to understand RAG architecture. In the next article we will create a RAG application from scratch with no complex tools.
Stay tuned!!
Video Explaination
Posts in this series
- Inside the Codebase: A Deep Dive Into Drupal Rag Integration
- Build Smart Drupal Chatbots With RAG Integration and Ollama
- DocuMentor: Build a RAG Chatbot With Ollama, Chroma & Streamlit
- Song Recommender: Building a RAG Application for Beginners From Scratch
- Retrieval Augmented Generation (RAG): A Beginner’s Guide to This Complex Architecture.